How to Generate Custom Reporting on Jira?
Jira is a powerful tool
As a Product Owner, I am using a lot Jira in the company I am working for. It’s my main tool and it’s a very common solution to manage software development. It comes with a lot of capabilities for managing Agile team, and lots of reports:
Feel the limits
But sometimes I feel a bit limited by the output generated by the tool. The more we are using it and feeding data in it, the more information I want to be able to read.
A typical exemple: for each task each user is providing the time spent for different activities: development, review, test… We are adding tags in the comment box of the work log:
![]()
So it’s really easy to put the data in Jira but there is no pre-built system to produce an analysis for each sprint and know how many time have been spent for #DEV or #TEST.
Or we are using Epics to track our most important features, but the time spent is at the Story level, there is no easy way to know how many time a specific Epic took.
Sometime a plugin can answer but I want to find a more generic solution to this issue. How can I produce the report I want to produce ?
Introducing the API and Jupyter
Jira comes with a very powerful REST API. So the data can be accessed by this way very easily.
Jupyter Notebook is an open-source web application that allows you to create and share documents that contain live code, equations, visualizations and narrative text.
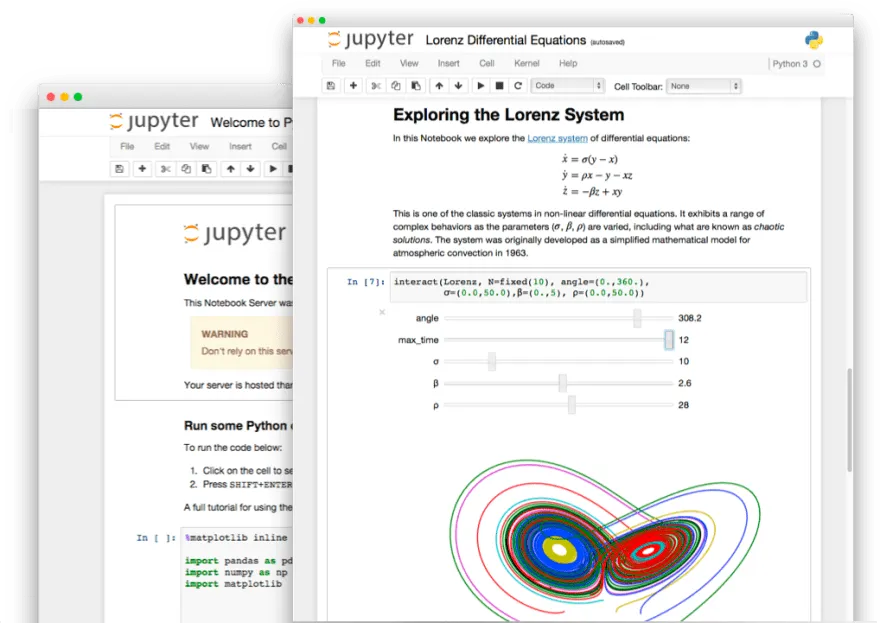
So yes, it’s possible to write a bit of python code that will connect to Jira Cloud (or Jira Server if you run Jupyter not so far away the Jira Server instance)
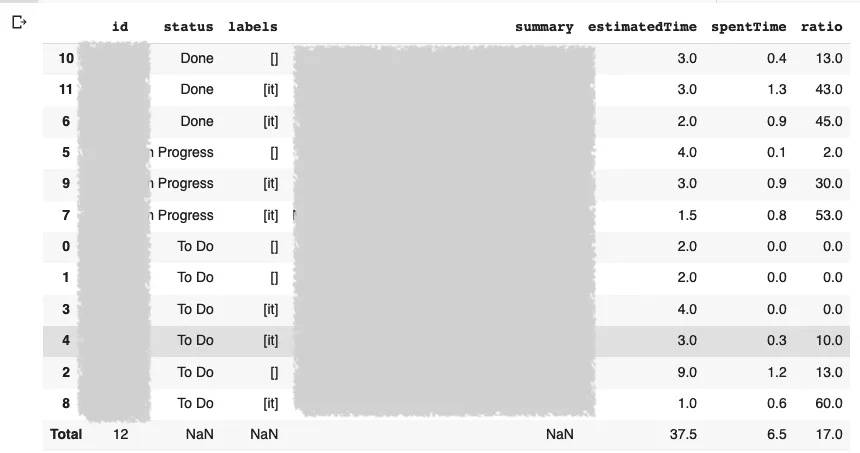
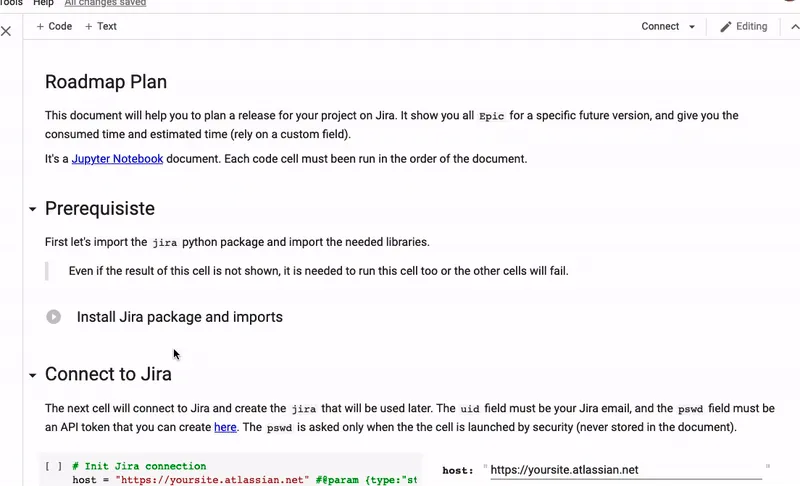
This small section will list all Epics for a specific project and a specific version, and generate a nice table (using pandas), with a footer for a sum of estimation.
# Show epics with consumed time and estimated time
project = "MYPROJECT"
version = "1.0.0"
issues = jira.search_issues('project = "{project}" and issuetype = "Epic" and fixversion = {version} ORDER BY key DESC'.format(project=project, version=version), maxResults=0,startAt=0)
formated_issues = list()
for issue in issues:
# compute estimated time
estimated = 0
if(issue.fields.customfield_10663):
estimated = issue.fields.customfield_10663
# compute spentTime from linked issues
spent_time = 0
child_issues = jira.search_issues('parent = {epic}'.format(epic=issue.key))
for child_issue in child_issues:
try:
spent_time += child_issue.fields.timespent
except TypeError:
# No spent time on this one !
spent_time += 0
formated_issues.append([issue.key, issue.fields.status.name, issue.fields.labels, issue.fields.summary, estimated, spent_time])
df = pd.DataFrame(formated_issues, columns=["id", "status", "labels", "summary", "estimatedTime", "spentTime"])
df["spentTime"] = round(df["spentTime"] /3600 /7, 1)
df['ratio'] = round(df['spentTime'] / df['estimatedTime'] *100, 0)
df = df.fillna(0).sort_values(["status", "ratio"])
df['id'] = df['id'].apply(lambda x: '<a href="https://mydomain.atlassian.net/browse/{0}">{0}</a>'.format(x))
df = df.append(pd.DataFrame([
[df.id.count(), df.estimatedTime.sum(), df.spentTime.sum(), round(df.spentTime.sum()/df.estimatedTime.sum()*100)]],
index = ["Total"],
columns=["id", "estimatedTime", "spentTime", "ratio"]))
HTML(df.to_html(escape=False))Here is the generated report (and yes there is a link to go directly on each case):
I have started by using this method with Jupyter, based on this article: Using Jupyter Notebooks to Access Jira. But (there is always a but! 😅) I was thinking that it’s too time-consuming to start the Jupyter via docker, and it’s not very easy to share a document to a co-worker:
OK send me the Jupyter file by email and give me the procedure to launch the Jupyter image on my computer. Oh wait, I need to start Docker too ?
There is probably a more easy way to do that no ?
Introducing Colaboratory
Colaboratory, or Colab when you are in a rush, is a service operated by Google that is running Jupyter notebook for you (yeah no more server to handle !). And it’s very easy to share notebooks via Google Drive or Github for example.
It’s not the only one (Azure Notebooks too) but our company is relying a lot on Google Drive, so it’s easier to share documents.
As of now I have written 6 or 7 notebooks that helps me dealing with Jira data:
- how to plan a 3-months roadmap for a new version,
- how to review my previous version and check why this Epic have not been delivered in time
- how to build sprint dashboard that give me a good vision of what have been done
- and so much…
Finally I can share with you some examples. I have created a dedicated repository on GitHub, so it is easy to generate a link to a specific notebook:
https://github.com/julbrs/jira-notebooks
One notebook on colab : jira_roadmap_plan.ipynb
Do not hesitate to create a PR on the repository if you want to share some nice looking notebook for Jira! Thanks for reading !